引用计数中惊艳的原子操作(一)
Contents
简述
所谓原子操作(atomic),就是不可分割的操作,在其操作所属期间,不会因为线程调度而被打断。
单处理器单核系统
在单处理器系统上,如果操作是在单个CPU指令中实现的,则该操作始终是原子的。
多处理器或多核系统
在多处理器系统上,确保原子性存在一点困难。要达到原子操作,就需要进行相应的处理。比如我们经常听到的自旋锁、互斥锁、信号量等线程同步方案。
本文旨在讲解 内存管理 -
引用计数中涉及到的原子操作,别有一番风味,请慢慢享用~
iOS 引用计数关键源码
在objc_object源码中,关于内存应用计数相关的方法,通过一个宏判断实现了两套逻辑,代码如下:
1 |
|
我们这里只分析SUPPORT_NONPOINTER_ISA下的objc_object::rootRetain,具体源码如下:
- 调用
retain,其实会来到这里,不做过多解释;
1 | ALWAYS_INLINE id |
源码中发现的问题
问题①:为什么要加一个
do while循环?问题②:
newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry);为什么不需要加锁等相关操作,那么该操作如何保证线程同步的呢?一个猜想: 莫非这个
addc加一操作是通过do while来实现原子操作的?
简化源码
- 精简掉 关于
SideTable存储引用计数的部分及isa.extra_rc++溢出后的处理
1 | ALWAYS_INLINE id |
slowpath 和 fastpath
1 |
- 这个指令是
gcc引入的,我们可以用__builtin_expect来向编译器提供分支预测信息; __builtin_expect(long exp, long c)代表的意思是:预测exp === c;
由此我们可以知晓,上述源码中:
!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)结果为0的可能性更大;- 也就是说这个
do while执行循环的可能性会比较小(不然是何其的消耗性能,这只是从代码层面上面的分析,这里提出,只是为了避免被这个do while纸老虎给哄住。我们继续);
我们从 do while 中的条件:while (slowpath(!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits))); 入手分析
重点来了~
LoadExclusive 和 StoreExclusive
Exclusive: 独有的;排外的;专一的;
在源码中StoreExclusive对于不同的处理器架构有三种不同的实现:
__arm64____arm____x86_64__ || __i386__
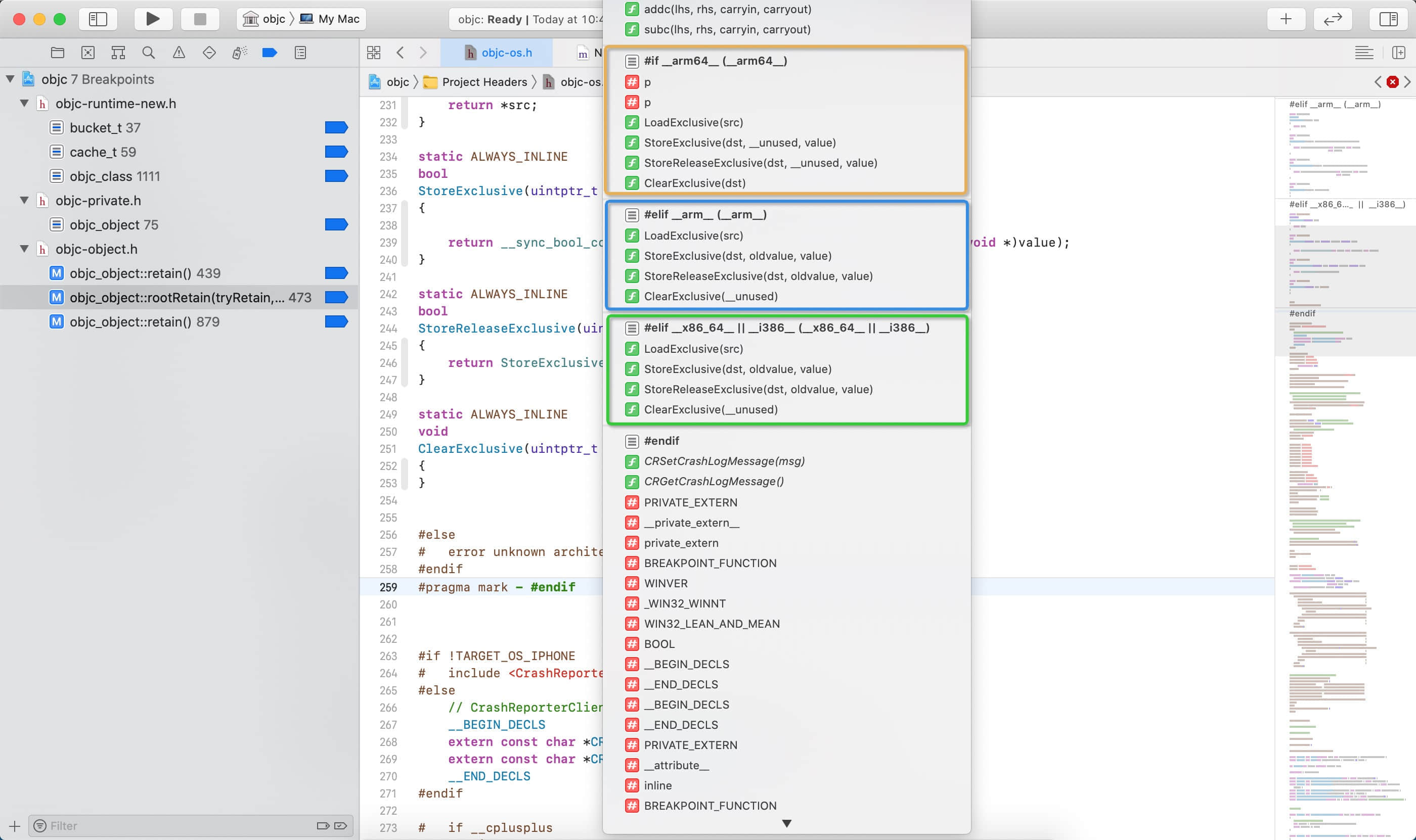
我们先从 arm64 开始分析
arm64
1 | // Pointer-size register prefix for inline asm |
- 如果不清楚
__LP64__的可以翻看我之前的一片文章; - 内部实现居然是
汇编,我们将重要的指令提出进行分析:ldxr和stxr指令; ldxr为LoadExclusive的重要内部实现stxr为StoreExclusive的重要内部实现
汇编指令: ldxr 和 stxr
- 这是
ARM中的原子操作指令,是不是发现了新大陆。
ldxr 指令
Load exclusive register
-
1
2LDXR Wt, [Xn|SP{,#0}] ; 32-bit general registers
LDXR Xt, [Xn|SP{,#0}] ; 64-bit general registers Wt:32位的通用寄存器名称,范围:0 ~ 31Xt:64位的通用寄存器名称,范围:0 ~ 31Xn|SP:64位的通用基址寄存器或堆栈指针,范围:0 ~ 31说明:
32位/64位代表寄存器的容量,范围可以理解为寄存器的编号
stxr 指令
Store exclusive register, returning status.
-
1
2STXR Ws, Wt, [Xn|SP{,#0}] ; 32-bit general registers
STXR Ws, Xt, [Xn|SP{,#0}] ; 64-bit general registers Wt:32位的通用寄存器名称,范围:0 ~ 31Xt:64位的通用寄存器名称,范围:0 ~ 31Ws:32位的通用寄存器名称,存储exclusive的状态Xn|SP:64位的通用基址寄存器或堆栈指针,范围:0 ~ 31说明:
32位/64位代表寄存器的容量,范围可以理解为寄存器的编号
关于
Exclusive accesses更多内容可以参考ARM开发者文档中对Exclusive accesses 的介绍
x86_64 || i386
1 | static ALWAYS_INLINE uintptr_t |
__sync_bool_compare_and_swap 内置函数
Compare And Swap,简称CAS;- 简单来说就是,在
写入新值之前, 先根据内存地址读出此刻内存真实值,然后与此刻操作期望值进行比较,当且仅当此刻内存真实值与此刻操作期望值一致时,才将此刻操作期望值写入,并返回true。 - 可能有点绕,联想着多线程的
数据竞争慢慢体会;- 比如:此刻期望将数据修改为10,但是由于多线程的缘故,此刻内存中的真实值并不一定为10,如果不为10,就不执行写入操作;
do while 循环的作用
1 | // 简化代码 |
这样就很直观了~
- 注意
while条件中的 取反操作!; - 如果写入不成功,那就一直执行循环,直到写入成功;
- 当然,由我们之前对
slowpath和LoadExclusive / StoreExclusive的分析,可知:预测分析执行循环的概率比较低,只有在线程数据竞争的时候发生;正常情况下,是不会进入循环的(执行一次do); - 有点
自旋锁的味道,慢慢体会;